
RIOXX have developed an Application Profile, which underpins the Guidelines for Open Access Repositories. It has been developed by UKOLN, Chygrove Ltd and Jisc, working closely with RCUK to provide a mechanism for institutional repositories in use in the UK Higher Education sector to comply with the RCUK Policy on Open Access. The ”first release of RIOXX focuses on applying consistency to the metadata fields used to record research funder and project/grant identifiers”.
I have been working with Paul Walk of RIOXX, to consider how the RIOXX application profile might be expressed in CERIF. The processed steps while transforming RIOXX into CERIF were as follows:
- Awareness of the use-case or purpose behind the RIOXX application profile
- Identification of relevant CERIF entities and their relationships underlying the profile
- Identification and assignment of RIOXX vocabulary terms
- Identification and assignment of RIOXX constraints / rules inline with the CERIF model and constructs
- Forward to the CERIF task group and the OpenAIRE community for validation and feedback
The transformation process started from an awareness of the use-cases or purpose behind the RIOXX application profile and guidelines. These have been designed “primarily with publications in mind” re-using the well-known “resource” entity from Dublin Core. Consequently, the underlying CERIF publication entity cfResultPublication in short cfResPubl is equally considered as a central entity. Further CERIF entities to underly the RIOXX profile have been identified as indicated in the image.
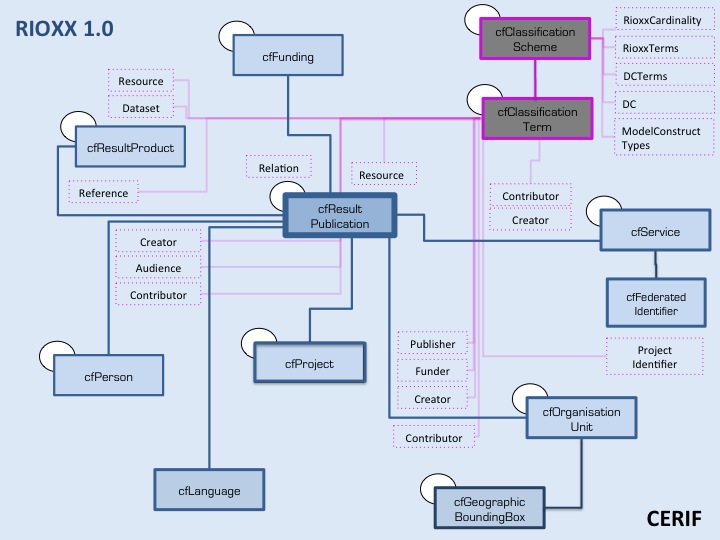
RIOXX Application Profile in CERIF – employed vocabulary and corresponding proposed classification schemes
The image reflects the RIOXX ‘concepts’ in CERIF; revealing a CERIF ‘ontology’. In CERIF, objects are effectively built through identifiers; a recently published CERIF Reference Document shows CERIF ‘object’ features as “Minor Classes”, and their identifier mechanism is explained with CERIF in Brief. The selection of CERIF entities is based on the mapping of the RIOXX Application Profile 1.0 elements to CERIF 1.5 elements.
RIOXX to CERIF Mapping
| RIOXX | CERIF |
|---|---|
| “resource” | cfResPubl |
| dc:title | cfResPubl.cfResPublTitle.cfTitle |
| rioxxterms:creator | cfResPubl.cfResPubl_Pers.PersId +cfResPubl.cfResPubl_Pers.cfClassId=”creator” cfResPubl.cfResPubl_OrgUnit.cfOrgUnitId +cfResPubl.cfResPubl_OrgUnit.cfClassId=”creator” cfResPubl.cfResPubl_Srv.cfSrvId +cfResPubl.cfResPubl_Srv.cfClassId=”creator” -> cfFedId.cfFedId |
| dc:identifier | cfResPubl.cfResPublId -> cfFedId.cfFedId |
| dc:source | cfResPubl.cfISSN |
| dc:language | cfResPubl.cfResPubl_Lang.cfClassId=”language” |
| rioxxterms:projectId | cfResPubl.cfProj_ResPubl.cfProjId +cfResPubl.cfProj_ResPubl.cfClassId=”projectIdentifier” -> cfFedId.cfFedId |
| rioxxterms:funder | cfResPubl.ResPubl_OrgUnit.cfOrgUnitId +cfResPubl.ResPubl_OrgUnit.cfClassId=”funder” -> cfFedId.cfFedId |
| dcterms:issued | cfResPubl.cfPublDate |
| dc:format | cfResPubl.ResPubl_Class.cfClassId=”e.g.jpeg” +cfResPubl.ResPubl_Class.ClassSchemeId=”dc” |
| dc:publisher | cfResPubl_OrgUnit.cfOrgUnitId +cfResPubl.ResPubl_OrgUnit.cfClassId=”publisher” -> cfFedId.cfFedId |
| dc:description | cfResPubl.cfResPublAbstr.cfAbstr |
| dc:subject | cfResPubl.cfResPubl_Class.cfClassId=”e.g.physics” |
| dc:rights | cfResPubl.cfResPubl_Class.cfClassId=”e.g.cc-by” |
| dc:coverage | Requires further elaboration as to whether and how e.g. the spatial, temporal, jurisdictional information is covered, because time, space or jurisdiction are constructs that are modeled different in CERIF. |
| dc:audience | cfResPubl.cfResPubl_Pers.cfPersId +cfResPubl.cfResPubl_Pers.cfClassId=”audience” -> cfFedId.cfFedId |
| dc:type | cfResPubl.cfResPubl_Class.cfClassId=”e.g.journal-article” Requires further elaboration. In Dublin Core it is a free text field, whereas in CERIF types are classes with their own identifiers; in an optimum space to anticipate a controlled vocabulary. |
| rioxxterms:contributor | cfResPubl.cfResPubl_Pers.cfPersId +cfResPubl.cfResPubl_Pers.cfClassId=”contributor” cfResPubl.cfResPubl_Srv.cfSrvId +cfResPubl.cfResPubl_Srv.cfClassId=”contributor” cfResPubl.cfResPubl_OrgUnit.cfOrgUnitId +cfResPubl.cfResPubl_OrgUnit.cfClassId=”contributor” -> cfFedId.cfFedId |
| dc:relation | cfResPubl.cfResPubl_ResPubl.cfResPublId +cfResPubl.cfResPubl_ResPubl.cfClassId=”relation” -> cfFedId.cfFedId |
| dcterms:references | cfResPubl.cfResPubl_ResProd.cfResProdId +cfResPubl.cfResPubl_ResProd.cfClassId=”dataset” -> cfFedId.cfFedId |
The mapping demonstrates the inherent conceptual differences between RIOXX and CERIF. E.g., the dcterms:creator element could be mapped to either a CERIF person, organisation or service identifier (cfPersId, cfOrgUnitId, cfSrvId), and in addition to a relationship between the “resource” i.e. CERIF publication and either a person, organisation, or service.
In CERIF e.g. “creator” is considered a role in a relationship and not an attribute of e.g. a publication or “resource” itself. Therefore, “Creator” is maintained as a classification term with its own identifier cfClassId=”creator”. The same holds for “contributor”, “publisher”, “funder”. Furthermore, in Dublin Core, a “resource” conceptually implies to underly all Dublin Core descriptions but “resource” is not an explicit element itself, and a direct mapping is therefore not possible. In general, a “resource” can either be e.g. a CERIF publication cfResultPublication in short cfResPubl, or e.g. data cfResultProduct in short cfResProd.
Note: There is awareness about the underlying ambiguities at repositories’ sides, and the RIOXX guidelines reflect these in their current version, by taking into account and therefore dealing with the legacy of current implementations.
A simple RIOXX to CERIF mapping has been presented in the table above. In addition to investigated exceptions with direct mappings, the RIOXX vocabulary has been identified. To formally describe this vocabulary in CERIF, requires its structure to follow the CERIF Semantic Layer sub model (see figure within CERIF in Brief), where namespaces as e.g. applied in RIOXX, such as, rioxxterms; dcterms; dc; reflect CERIF Classification Schemes to which identified terms are assigned, as indicated in the image above. The mapping in addition revealed, that due to conceptual differences in between the two formats – namely RIOXX and CERIF, rules will have to be developed. E.g. Language is an entity in CERIF as well is a Title, and therefore no vocabulary is needed. Rules may be required, such as with the RIOXX Cardinality, and a formal mapping requires model construct types to reflect entities of the two formats:
- RIOXXTerms: Creator; Funder; Contributor; Project Identifier
- DCTerms:
Issued; Audience; Reference - DC:
Identifier;Language;Source;Title;Description;Format; Publisher;Rights;Subject;Coverage;Relation; - RIOXXCardinality: OneOrMore; ExactlyOne; ZeroOrMore; ZeroOrOne
- ModelConstructTypes: Entity; Attribute; Relationship; Term; Scheme; Element
In CERIF, rules would currently be encoded as a vocabulary. The proposition is therefore, to extend the CERIF vocabulary following the RIOXX Profile’s requirements anticipating the formal CERIF syntax and declared semantics (Semantic Layer). These rules could look as follows; their formal application enabled by the CERIF link entity cfClass_Class through the two inherent identifiers, cfClassId1 and cfClassId2 upon which a rule’s state (e.g. active; inactive) could be further indicated (not yet considered below).
- Describing Cardinality “one or more” within the proposed “RioxxCardinalityScheme”:
cfClass.cfClassId=”OneOrMore”
cfClass.cfClassSchemeId=”rioxxCardinality”
- Applying the “one or more” cardinality description to the “Creator” relationship:
cfClass_Class.cfClassId1=”rioxxTerms:creator”
cfClass_Class.cfClassId2=”rioxxCardinality:oneOrMore”
Summarising the investigations and mappings, further thought and feedback is required. A formal extension proposal document will be prepared for continued discussion within the CERIF TG and the wider community, where also the vocabularies’ and the terms’ identifiers need discussion. The current proposal adds a federated identifier cfFedId.cfFedId as placeholder reference for persistent identifiers (e.g. ORCID with person; FundRef with Funders, etc.).
The entire formal representation of the above presented RIOXX Application Profile Version 1.0 will be made available in CERIF XML for download and further investigation, and to supply unambiguous description of the current draft and proposal, not least also for comparison with ongoing related activities such as OpenAIRE, where a CRIS Interoperation Profile in CERIF XML is being developed. It will be presented at the euroCRIS Membership Meeting in Bonn – May 13th, 2013.
The RIOXX team posts updates on the RIOXX blog.
Further Links:
- Application Profiles Support Project: http://www.ukoln.ac.uk/projects/ap/
- Scientific Data Application Profile Scoping Study Report by Alex Ball, UKOLN, University of Bath, UK: http://www.ukoln.ac.uk/projects/sdapss/papers/ball2009sda-v11.pdf
- CERIF 1.5 Release: http://www.eurocris.org/Index.php?page=CERIF-1.5&t=1
- CERIF 1.5 Reference Document: http://www.eurocris.org/Uploads/Web%20pages/CERIF-1.5/cerif.html
- RIOXX Blog: http://rioxx.net



