With previous posts we introduced the mapping work to transform the REF XML Reporting Profile to CERIF XML (and vice-versa):
- REF Reporting Profile in CERIF (Intro)
- REF Reporting Profile in CERIF (Entities)
- REF Reporting Profile in CERIF (Vocab)
- REF Reporting Profile in CERIF (Terms)
After quite a journey and some months later we now publish the current CERIF XML files to share them with the community for further discussion even if they are not as polished as initially planned. It is important to note, that the files did not undergo a final testing nor evaluation to this point. However, they are syntactically valid CERIF 1.6 XML and have been prepared thoroughly. To prevent from further delay and to not risk that the files will not be published and thus un-usable at all, we provide them for continued improvements and for further elaboration as such – this is important especially with respect to semantics.
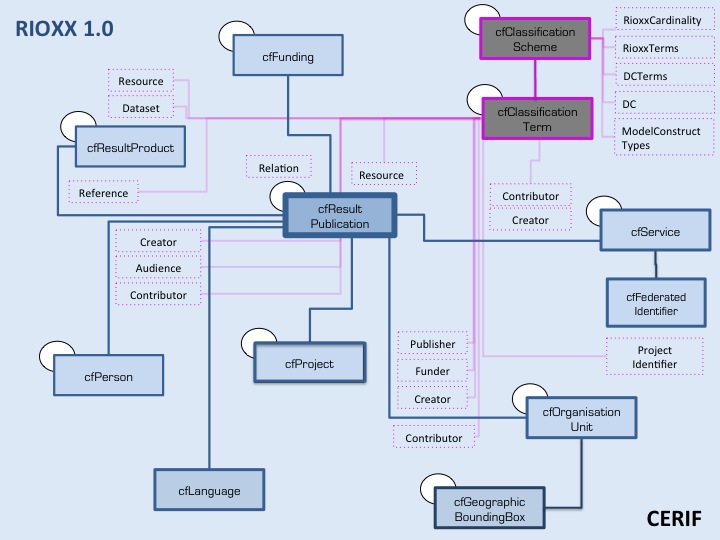
We consider the files a very valuable contribution for the guidance of future CERIF activities. They do demonstrate the complexity imposed by a multitude of applicable vocabularies and show the need for contextual clarity when defining boundaries, aggregation and governance levels.
It has to be mentioned here, that the “REF Reporting Profile in CERIF” was not a profile built according to REF Guidelines but a profile aimed at transforming a REF2014 XML file (following the REF Guidelines) into a CERIF XML file with an awareness of the substantial underlying structural differences at both ends – including that the data will finally have to be validated by the REF XML mechanism according to the guidelines (that is, e.g. the length of a string or the cardinality of values). It is for this reason also that a decision was taken, to use the REF XML element names as identifiers for the CERIF vocabulary terms whenever possible, to simplify the automated transformation script maximally and to ensure the recognition of the corresponding elements or hence terms (see below xml examples). This is also in support of a human understanding when examining the files. People familiar with CERIF will know that there is quite a number of required identifiers (often non human readable) within CERIF entities to enable the interlinkage or aggregation of objects; which may indeed be a challenge for the human reader (please have a look at the Excel Sheet comment column).
To provide for better access to the files – again for the human reader – the bulk reporting profile has been split into separate files:
- Common Fields (mandatory with each submission) in CERIF 1.6 XML
- Research Groups in CERIF 1.6 XML
- Staff in CERIF 1.6 XML
- Outputs in CERIF 1.6 XML
- Impact and Contacts in CERIF 1.6 XML
- (Vocabulary) in CERIF 1.6 XML
Within the reporting files, the applied vocabulary terms (cfClassId) and their corresponding namespaces (cfClassId) are indicated by identifier references where the controlled vocabulary (cfClassId/cfClassSchemeId) itself is maintained in the vocabulary file.
For a quick reference we also provide an Excel Sheet of the profile. Its xml2xml tab covers all the involved entities and fields and indicates the explained structure. Its vocabularies tab collects all controlled terms (and their identifiers) except from those which are expected to be provided by the submitting institution themselves (hence a ‘institution’ prefix in the cfClassificationSchemeId column of the Excel). Examples of relevant institutional vocabulary terms are available with the vocabulary file and should be retrievable via the cfClassSchemeId field and the prefix ‘institution’ instead of ‘ref’.
If submitted in pieces and not in one bulk file, each object has to a) identify the reporting institution by provision of the UK Provider Reference Number (UKPRN) b) indicate multiple submissions and c) refer to the REF’s Units of Assessment.
The following snippets from REF XML and REF in CERIF XML provide insight into inherent structural differences. The complexity increases (not shown in the snippets) with CERIF relationships and furthermore with multiple vocabularies and definitions for possible aggregations and objects at a given time:
A REF2014 XML Snippet
<ref2014Data xmlns="http://www.ref.ac.uk/schemas/ref2014data">
<institution>10006840</institution>
<submissions>
<submission>
<unitOfAssessment>9</unitOfAssessment>
<multipleSubmission>A</multipleSubmission>
</submission>
</submissions>
</ref2014>
The corresponding CERIF XML Snippet
<!-- REF 2014 XML in CERIF -->
<CERIF xmlns="urn:xmlns:org:eurocris:cerif-1.6-2" xsi:schemaLocation="urn:xmlns:org:eurocris:cerif-1.6-2 http://www.eurocris.org/Uploads/Web%20pages/CERIF-1.6/CERIF_1.6_2.xsd" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" date="2013-09-22" sourceDatabase="REF Common Fields">
<!-- -->
<cfOrgUnit>
<!-- for the identification of a submission -->
<cfOrgUnitId>10006840</cfOrgUnitId> <!-- UKPRN number *mandatory* -->
<cfOrgUnit_Class>
<cfClassId>institution</cfClassId>
<cfClassSchemeId>ref-organisation-types</cfClassSchemeId>
</cfOrgUnit_Class>
<cfOrgUnit_Class>
<cfClassId>A</cfClassId>
<cfClassSchemeId>ref-multiple-submissions</cfClassSchemeId>
</cfOrgUnit_Class>
<cfOrgUnit_OrgUnit>
<cfOrgUnitId2>9</cfOrgUnitId2>
<cfClassId>unitOfAssessment</cfClassId>
<cfClassSchemeId>ref-organisation-categories</cfClassSchemeId>
</cfOrgUnit_OrgUnit>
</cfOrgUnit>
<!-- -->
</CERIF>
Many thanks again to Gareth Edwards (HEFCE) who was very supportive in explaining the meaning behind fields and structures which initially were not entirely clear.
The files are now available for further testing. An XSLT Transformation Script is available upon request to generate REFXML from CERIF XML (it needs a bug-fixing). We shall see upon feedback and responses how to proceed with it.